[딥러닝/AI] ChatGPT 5분동안 빠르게 사용 해보기 (3/17 Updated)
DALL-E2, GPT-3 등으로 유명한 OpenAI 에서 인공지능 챗봇 ChatGPT 를 공개했다.
What’s ChatGPT?
- GPT-3.5 기반으로 하는 ChatGPT의 가장 큰 특징은 대화 방식으로 연속적인 질문과 답변 을 주고 받으면서 원하는 task 를 수행할 수 있다는 점이다
- 카테고리 분류, 대화 생성, Q&A, 문서 및 대화 요약, 심도 있는 토론, 코드 작성, 코드 리뷰 등 모두 수행 가능
-
InstructGPT 와 동일한 방법으로 학습한 형제 모델이라고 하지만, 생성한 문장을 사람(AI Researcher)이 평가하고, 사람의 피드백에 따른 강화학습(RLHF) 으로 재학습함 으로써 AI 에서 가장 이슈가 되는 ethical issue 도 개선할 수 있었다고 한다
-
구글과 같은 검색엔진으로 답변을 우리가 직접 찾아야 했지만, ChatGPT는 우리가 원하는 답변만 쏙쏙 준다는 점이 가장 큰 차이인 것 같다.
-
일반적인 챗봇이나 Q&A 서비스가 생각나는데, 가장 최근에 퀵하게 써봤던 서비스는 Azure 에서 document를 input 으로 주면, Q&A가 가능한 QnA Maker와 Azure Cognitive Service 였던 것 같다.
ChatGPT 사용해보기
아래 링크 누르고 sign up 하면 ChatGPT를 직접 사용해 볼 수 있다
질문1. 파이썬이 무엇인가?
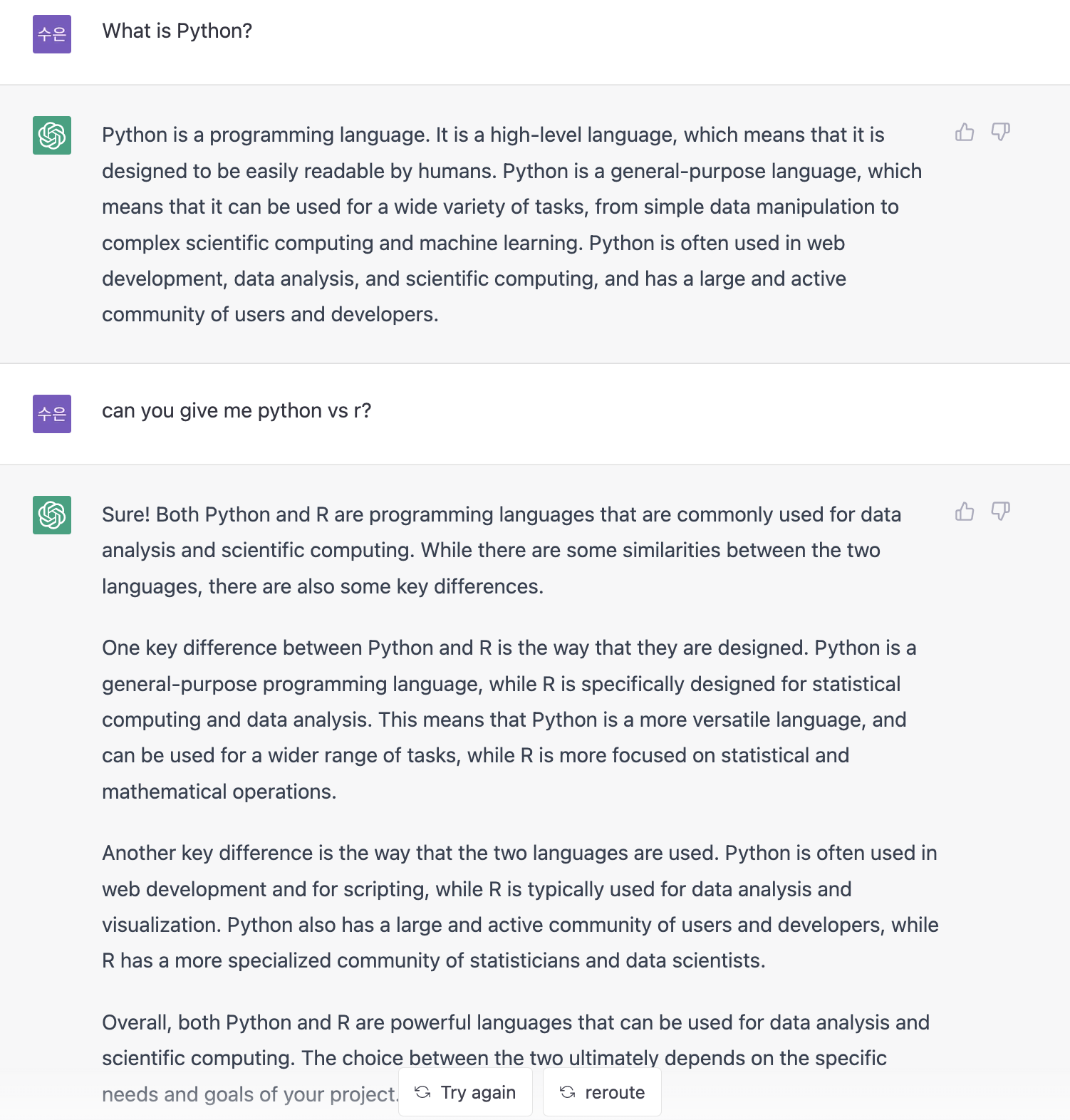
질문2. Python 과 R 을 비교해줘
Python과 R 을 비교해달라고 하고, 너무 기니까 두 문장으로 짧게 말해 달라고 하는데, 요구사항을 꽤 정확하게 받아서 대답한다..!
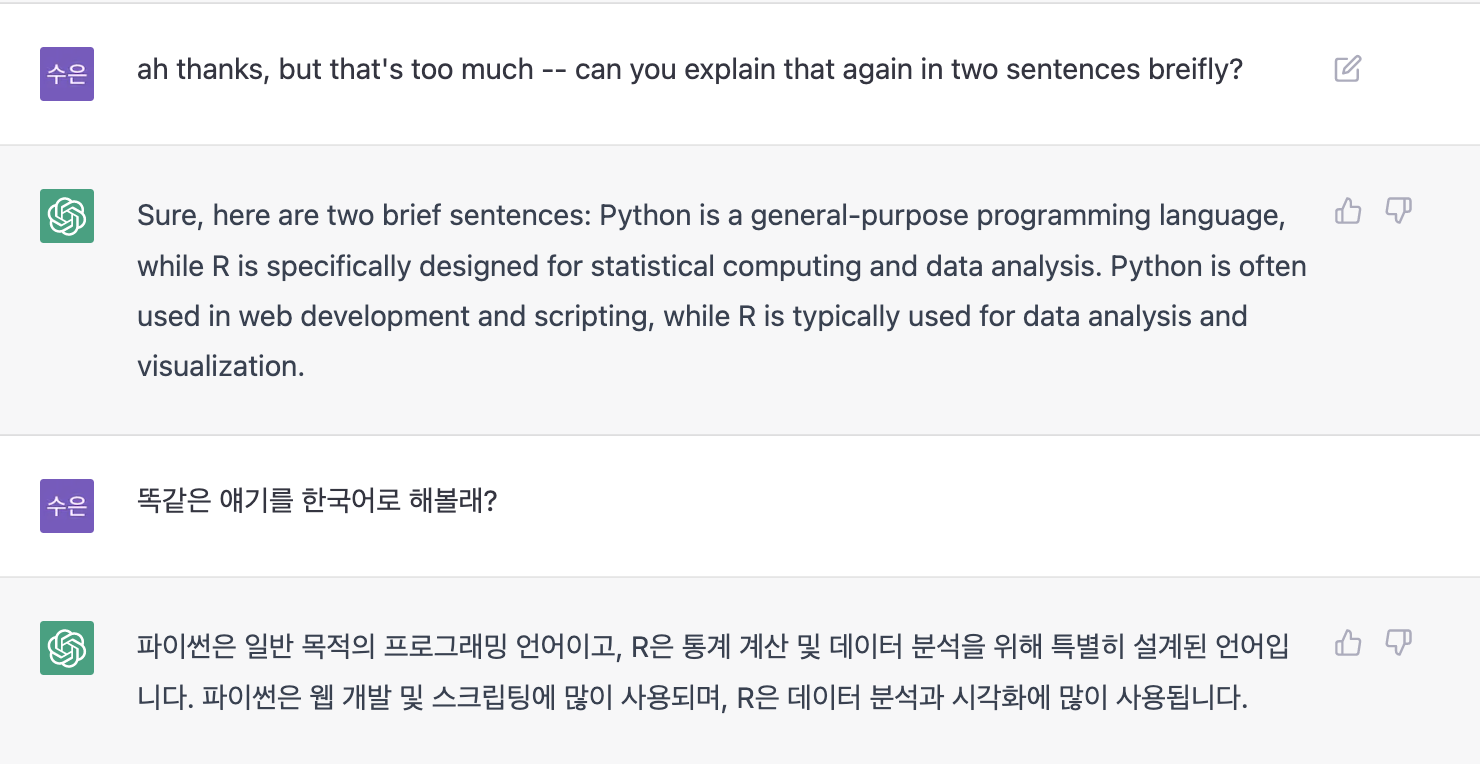
이번엔 말도 안되는 내용을 질문해봤다.. web search 가 안될텐데,, 모른다고 대답하네!?

간단 후기
- 확실히 영어 답변이 빠르고, 한국어 답변은 속도가 느린게 체감이 된다
- 모르는 걸 모른다고 말하는 똑똑함..!!
-
[1/18 Update] Azure 에 Open AI 서비스가 런칭된다는 소식이 들려오며, GPT3.5, Codex, DALL-E2 등 초거대 AI 모델을 클라우드 Azure 상에서 사용할 수 있게 된다. NLP 서비스에 특히 특화된 Azure 에 한번더 strength 가 더해지는 느낌 곧 $20/month 형태의 구독도 출시된다고 했는데, 베타 버전과 어떻게 다른지 이것도 한번 써봐야겠다
23/3/17 Update
OpenAI 에서 GPT-4 를 발표했다. API waitlist 를 받는 걸 보니, API 는 곧 오픈할 예정인 듯 하다.
- Waitlist 신청 시 “Are there specific ideas you’re excited to build with GPT-4?” 라고 묻는 걸 보니, 활용 가능한 아이디어를 수집하는 목적으로 묻는 것 같다.
초거대 모델이 연이어 출시됨에 따라 드는 생각은..
막대한 GPU 를 바탕으로 한 컴퓨팅 자원으로 많은 기업들이 billion 단위의 hyper-parameter 의 모델을 학습하고 출시하고 있다.
개인적으로 1) 특화된 분야에서의 신뢰성 2) 모델의 경량화 가 key 일 것 같다는 생각이 든다.
ChatGPT 가 엄청난 붐을 일으키며 언어 생성모델에 대한 관심이 뜨거워졌고, 일반적인 챗봇 서비스 기능과 같이 general use case 에는 적합한 모델 이라고 개인적으로 생각된다.
하지만, 2021년도까지의 데이터를 학습 데이터로 사용했기 때문에 최근 정보에 대한 정확도는 당연히 떨어질 수 밖에 없다.
AI모델이 오류가 있는 데이터를 학습해 틀린 답변을 맞는 말처럼 "그럴듯"하게 답변을 제시하는 현상을 Hallucination 이라고 하는데, ChatGPT 의 답변이 진실 여부와 워낙 복잡한 모델이기 때문에, 출처가 어디인지도 알기 힘들고, 논리적이고 그럴싸한 답변을 하기 때문에, 사용자(User) 입장에서는 잘못된 정보를 수용해 틀린 의사결정/판단을 할 수 있다.
지금 같이 초거대모델 의 “레드오션” 에서 기업이 살아남기 위해서는 어떤 전략이 필요할까?
특정 분야에는 이 모델이 믿을 수 있다. 최고다. 라는 전략 이 필요하지 않을까?
예를 들어, 제약이나.. 또는 에너지 분야가 있다고 했을때, 해당 분야의 신뢰도 높은 데이터를 학습한, 신뢰성이 보장된 “특화된” 모델이어야 고객사 입장에서 해당 모델을 “믿고” 사용할 수 있을 것 같다.
또 하나는, 경량화의 관점 즉, 유지/운영 비용이 합리적인 수준인가 일 것 같은데, 엄청난 수의 파라미터로 학습한 모델은 성능 관점에서는 많이 학습시킬 수록 더 “똑똑“해지겠지만, 운영/유지 비용을 생각하면 무작정 학습만 계속 시킨다고 능사는 아닐 것 같다. 모델이 “잘” 사용되기 위해서는 balance 가 좋아야한다고 생각이 드는데, 충분한 수준의 학습과 동시에, 모델이 너무 무겁지 않게 경량화된 모델을 구현하는 것이 고객사/현업에서 사용되는 데에 어쩌면 가장 중요한 부분이라고 생각한다.
또 하나의 생각은, 언어 모델이 발전됨에 따라 기계번역 측면에서는 거의 문제없다고 볼 정도로 훌륭한 성능을 보여준다고 느껴졌는데, 그렇다면 fine-tuning 을 한국어로 조금 시킬 수 있다면, 굳이 한국어-특화된 모델이 필요할까? 라는 생각도 들었다.
두런두런 썼지만, 결국 국내외 기업들에서 출시되는 초거대 모델들이 어떤 분야에 특화되어 점점 develop 되고 자리를 잡을 지 지켜보는 것도 재미있을 것 같다.
댓글남기기