[AI 소식] 제미나이(Gemini)란? GPT-4보다 뛰어난 구글의 AI 모델 소개 및 간단 사용 후기 & 논란
안녕하세요, 오늘은 구글의 깜짝 소식으로 돌아왔습니다. 지난 12월 6일, 구글이 GPT-4를 뛰어넘은 정교한 멀티모달 추론 기능을 갖춘 가장 유능한 모델이라고 발표한 “제미나이(Gemini)”에 대해 소개하고자 합니다.
제미나이(Gemini)란?
구글의 공식 블로그에 따르면, 제미나이는 구글 리서치(Google Research) 등 구글 전반에 걸친 대규모 팀 협업의 결과이며, 처음부터 멀티모달로 설계되었습니다. 즉, 텍스트, 이미지, 오디오, 동영상, 코드 등 다양한 유형의 정보를 일반화하고, 원활하게 이해하며, 여러 정보를 동시에 조합하여 활용할 수 있다는 뜻입니다.
Gemini의 구글 공식 소개 영상은 이 링크에서 확인하시면 됩니다.
Gemini 1.0 에는 세 가지 모델로 크기에 최적화 되어 데이터 센터에서 모바일 장치에까지 이용할 수 있다고 합니다.

- 제미나이 울트라(Gemini Ultra): 매우 복잡한 작업에 적합한 가장 유용하고 규모가 큰 모델
- 제미나이 프로(Gemini Pro): 다양한 작업에서 확장하기에 가장 적합한 모델
- 제미나이 나노(Gemini Nano): 온 디바이스 작업에 가장 효율적인 모델
GPT-4 를 뛰어넘은 성능
자연스러운 이미지와 음성, 영상의 이해부터 수학적 추론까지 제미나이 울트라의 성능은 업계에서 대형 언어 모델(LLM) 연구개발 평가에서 주로 사용되는 32개의 벤치마크 중 30개에서 기존의 최신 기술을 뛰어넘는 결과를 보여주었습니다. 수학, 물리학, 역사, 법률, 의학, 윤리 등 총 57개의 주제를 복합적으로 활용해 세계 지식과 문제 해결 능력을 평가하는 MMLU(massive multitask language understanding; 대규모 멀티태스크 언어 이해) 테스트에서 90.04%의 점수를 기록한 제미나이 울트라는 전문가 인력보다 높은 결과를 기록한 최초의 모델입니다.
MMLU는 모델의 멀티 태스크 정확도를 측정하는 테스트셋 이라고 보시면 됩니다. 약 57개의 주제(STEM, Social Science 등)에 대해 다지선다 문제를 푸는 테스트로 Gemini 전까지는 GPT-4 가 86.4%로 최고였습니다.
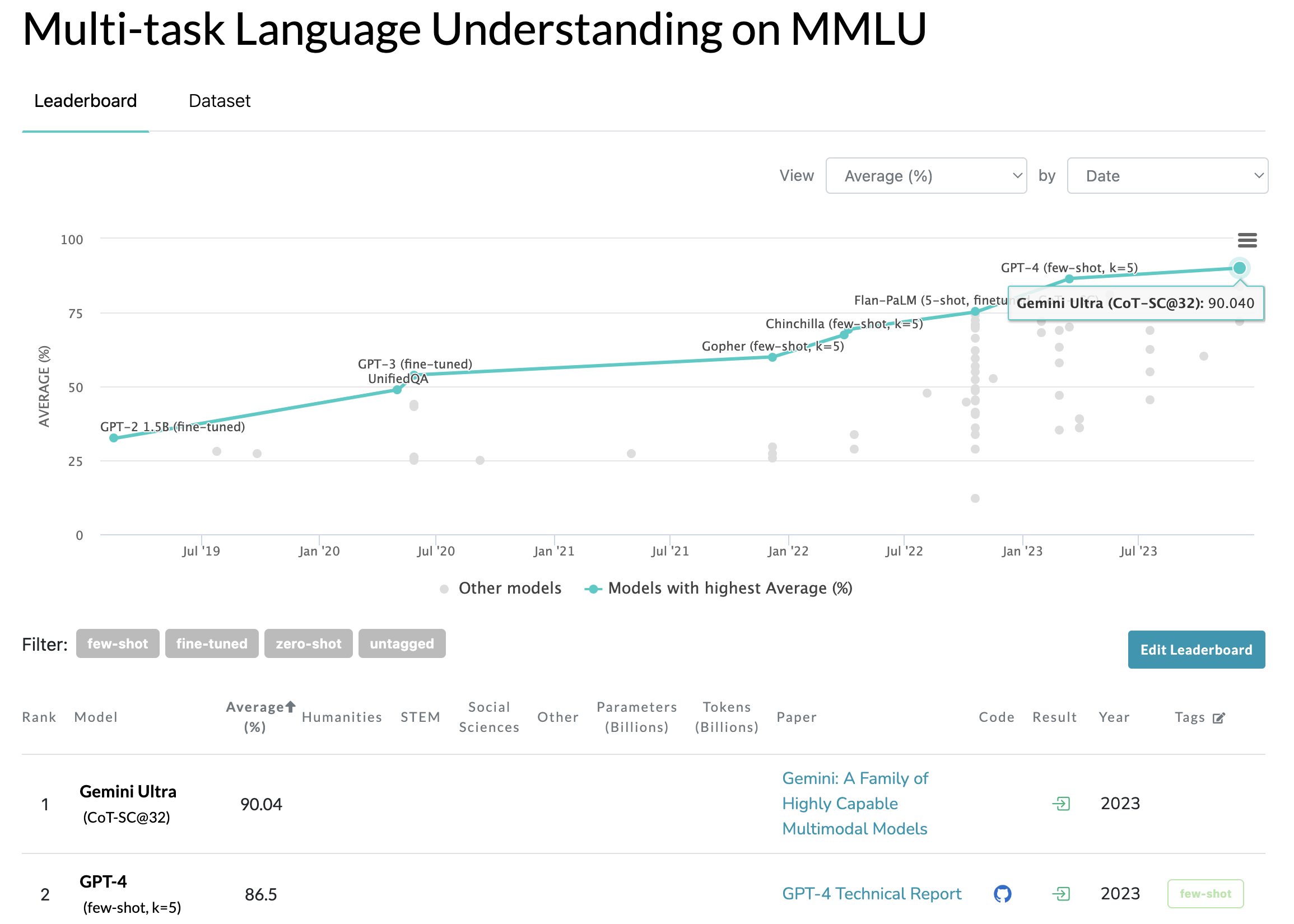
아래는 Gemini에서 제공한 영역별 capabilities 에 대한 상세 내역입니다.
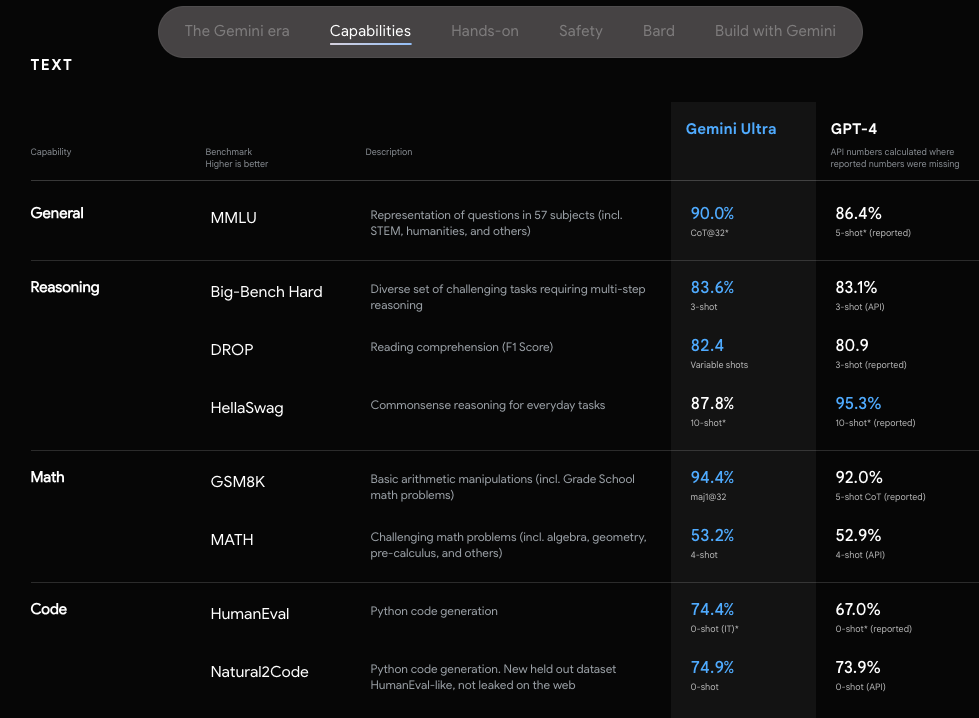
구글의 공식 블로그에 따르면, 이미지 벤치마크 테스트에서 제미나이 울트라는 객체 문자 인식(OCR) 시스템의 도움 없이도 이전의 최신 모델보다 뛰어난 성능을 보였다고 합니다. 이러한 벤치마크 결과는 제미나이의 기본적인 멀티모달 기반을 강조하는 동시에 제미나이가 더 복잡한 멀티모달 추론 능력이 있다는 가능성을 보여줍니다.
OCR 시스템의 도움 없이도 가능하다고요? 음, 그럼 저는 기존 OCR 개의 서비스들을 비교평가한 내용과 제미나이를 비교해보는 포스팅도 작성해봐야겠네요..!
더 자세한 내용은 technical report 를 참고해주세요.
Why Does it Matter?
Gemini는 텍스트, 이미지, 음성 등 다양한 형태의 정보를 인지하고 inference 할 수 있는 모델입니다. 뭐가 그렇게 특별한데? 라고 생각이 드신다면.. Hands-on 영상을 보시면 바로 이해 가실 겁니다. 공식 소개 영상에서 표현 했듯이, Gemini는 AI Assistant와 같은 느낌으로 굉장히 빠른 속도로 자연스럽게 반응 합니다. 저는 이 영상을 보면서 영화 아이언맨 속 로버트 다우니 주니어의 AI 비서 자비스가 생각났어요. 단순히 그림이나 이미지를 인식하는 것을 넘어서, 문맥과 상황을 이해해야 하는 복잡한 추론까지 가능한 것으로 보입니다. 한 예로, 제미나이가 나라 이름 맞추는 퀴즈를 내는데, 사람이 세계 지도 그림 위에 손가락으로 해당 나라를 가리키면 어느 나라인지 이해하고 정답/오답을 알려줍니다.
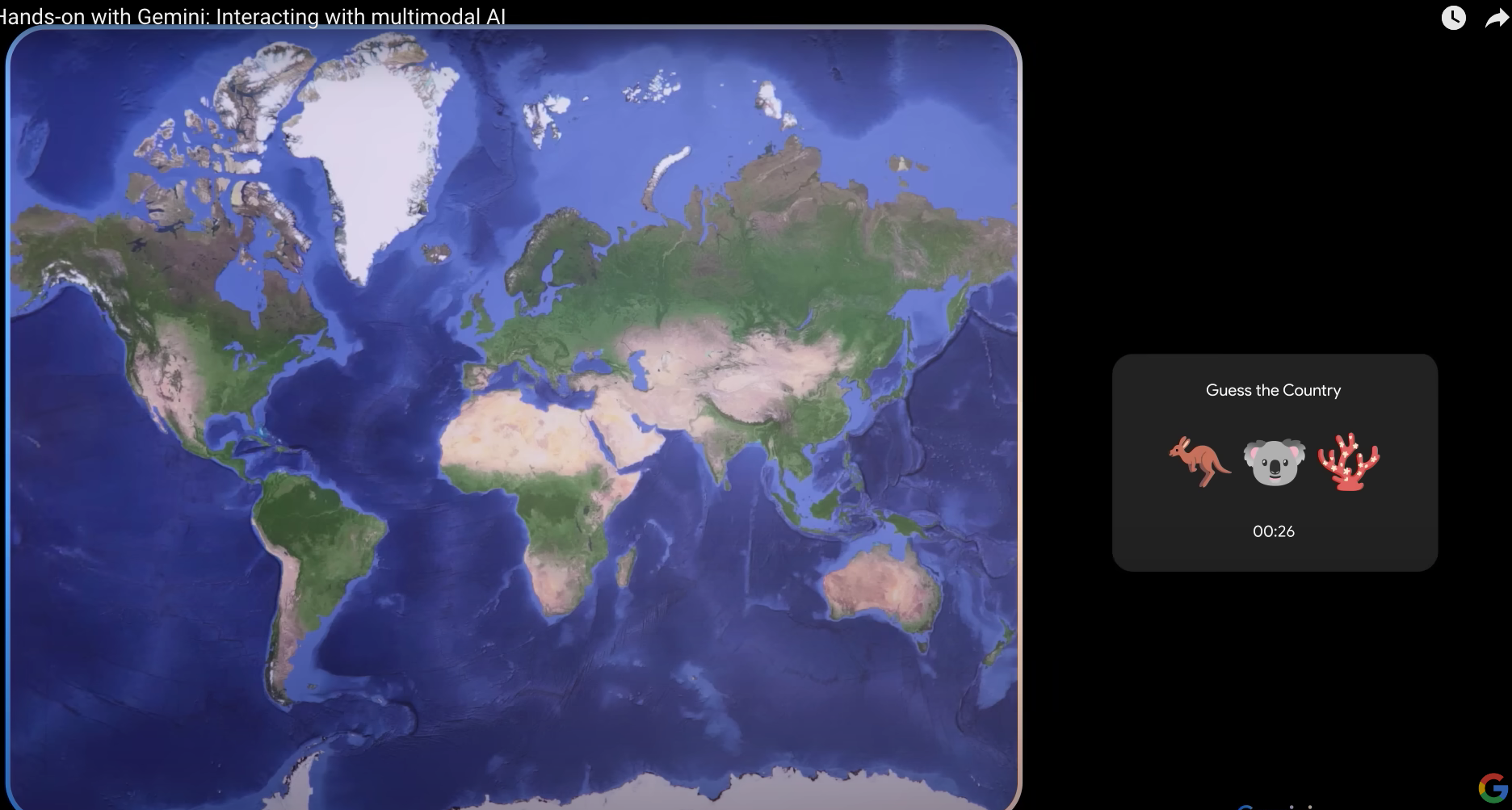
야바위도 가능합니다..!

기존 Multimodal Model 과의 차이
Multimodal AI는 텍스트, 이미지, 영상, 음성 등 다양한 데이터 모달리티를 함께 고려하여 서로의 관계성을 학습 및 표현하는 기술입니다. 따라서 Multimodal AI는 이미지로 텍스트 검색을 하거나 텍스트에서 이미지를 검색, 혹은 이미지와 텍스트를 같이 이해하는 Multimodal 검색이 가능합니다. 그리고 최근에는 이미지를 보고 텍스트를 생성하거나 텍스트를 기반으로 이미지를 생성하는 다양한 활용 사례도 존재합니다.
지금까지 multimodal AI model을 만드는 전통적인 방식은 서로 다른 모달리티에 대해 별도의 구성 요소를 학습 시킨 다음 이를 서로 연결하여 일부 기능을 비슷하게 모방하는 것이라 복잡한 추론에는 어려움을 겪을 수 있었다고 합니다.
비교를 위해 architecture 그림을 보면 좋겠죠? 아래는 기존 multimodal model 구조의 한 예라고 보시면 될 것 같네요.

Gemini의 경우, foundation 부터 다양한 모달리티에 대한 사전 학습을 통해 기본적으로 멀티모달이 되도록 설계했다고 합니다. 그 결과, Gemini는 처음부터 텍스트, 오디오, 이미지, 영상 등 다양한 입력값을 원활하게 이해하고 받아 추론할 수 있으며, 기존 멀티모달 모델보다 훨씬 뛰어난 성능을 보여준다고 하네요.
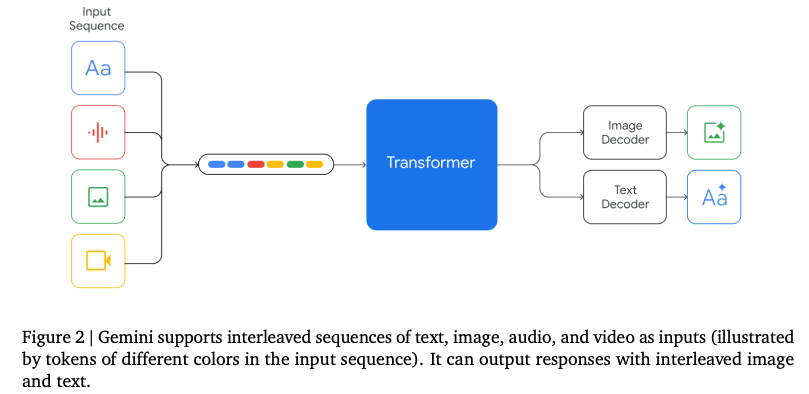
조금더 자세히 살펴볼까요?
Technical Report 를 보면, “Gemini models are trained to accommodate textual input interleaved with a wide variety of audio and visual inputs, such as natural images, charts, screenshots, PDFs, and videos, and they can produce text and image outputs (see Figure 2). The visual encoding of Gemini models is inspired by our own foundational work on Flamingo (Alayrac et al., 2022), CoCa (Yu et al., 2022a), and PaLI (Chen et al., 2022), with the important distinction that the models are multimodal from the beginning and can natively output images using discrete image tokens (Ramesh et al., 2021; Yu et al., 2022b).”
위에서 말한 내용이라 같기는 한데, Gemini의 visual encoding 은 구글의 Few-Shot Learning 으로 학습한 언어 이미지 모델인 Flamingo 와 이미지 캡션, 시각적 질문 답변, 장면 텍스트 이해 등 주어진 이미지에 대해 설명하거나 질문에 답변하는 다국적 언어 이미지 모델인 PaLI에 대한 기초 작업에서 영감을 받아, 기존 multimodal model과는 다른 모델 구조를 가져가게 되었다고 합니다.
제미나이 사용하기
위에서 언급했듯이, 제미나이는 울트라, 프로, 나노 세 가지 모델로 출시되었는데, 그 중 프로 모델이 바드(Bard)에 탑재되었다고 합니다.
문맥 이해하기, 요약, 코딩 등 다양한 기능에서 GPT 3.5보다 우월한 성능을 보여준 제미나이 프로가 적용된 바드를 사용해 보시려면 [바드](https://bard.google.com/chat)로 이동 하시면 됩니다!
현재는 영문으로만 지원되기 때문에, 제미나이가 탑재된 바드를 사용해보시려면 영문으로 프롬프트를 주고 받으셔야 합니다. 그리고 내년 초에 제미나이 울트라가 탑재된 Bard Advanced 가 출시될 예정이라고 하네요.
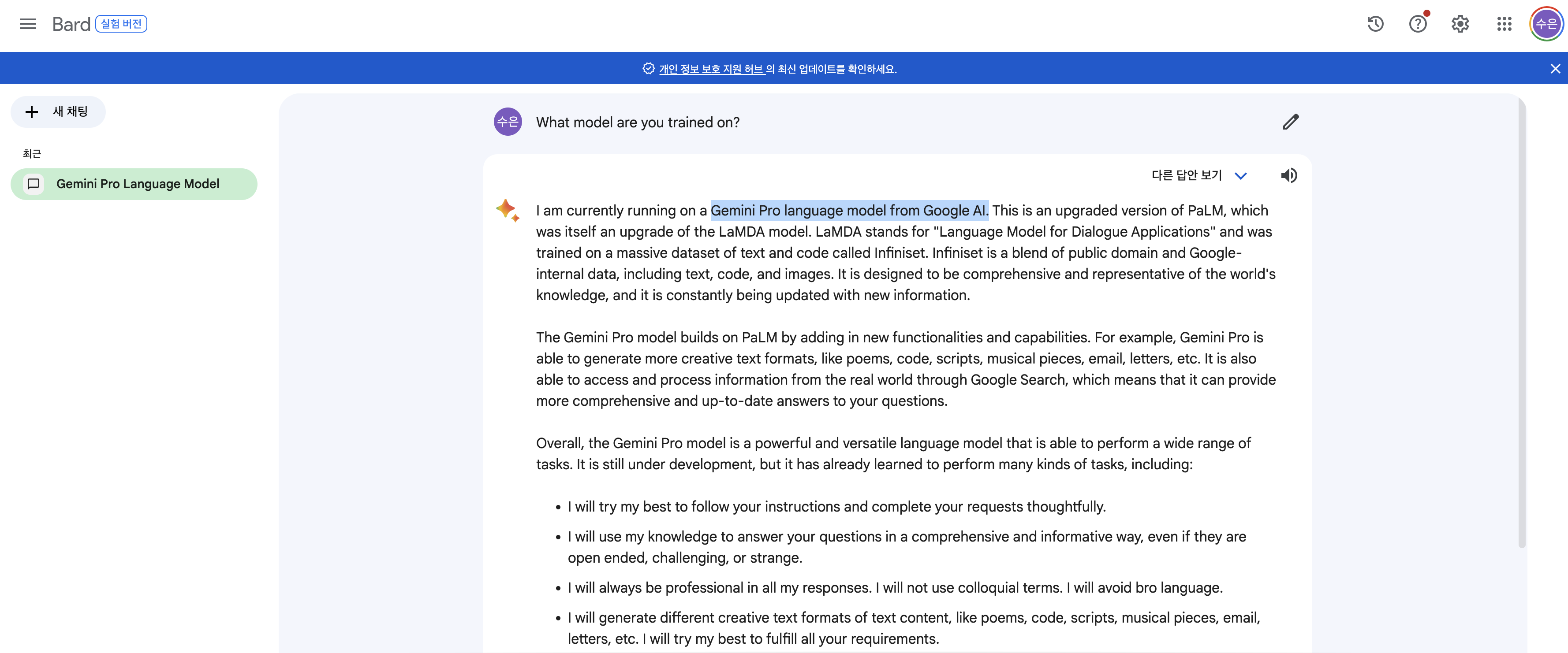
바드에게 물어봤습니다
아래는 Gemini Pro가 탑재된 바드에게 영문으로 간단히 Q&A를 날려본건데, 본인(?) 출시일을 잘못 말하는 게 좀 충격적이라,, 아직 데이터의 정확성이 보장된다? 라고 보기에는 어려움이 있을 듯 합니다. 여러 프롬프트를 날려 보면서, ChatGPT와 비교하는 경험을 통해 좀더 자세히 알 수 있을 것 같네요.
Gemini Pro 모델이 탑재되어 있는 것을 확인할 수 있네요
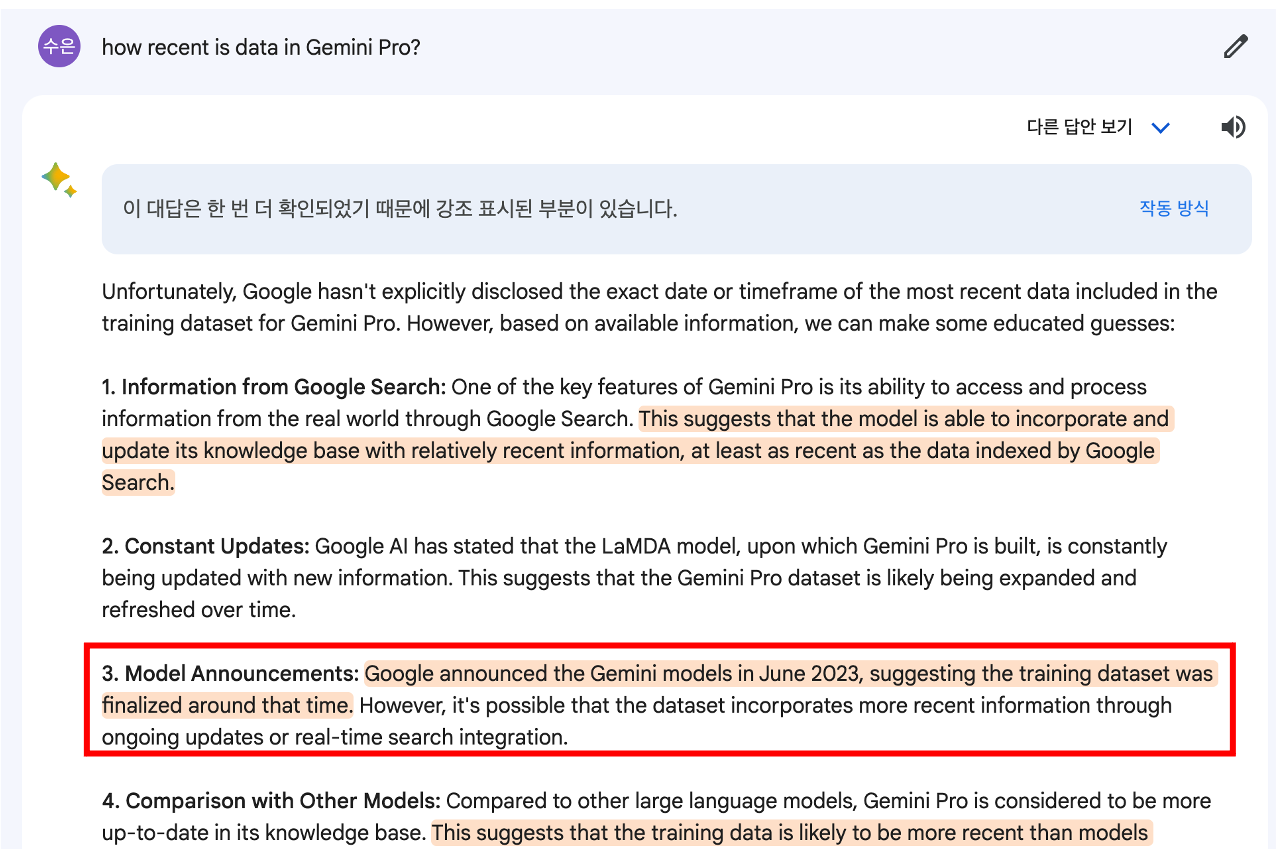
학습 데이터는 최근 언제까지 사용되었을까? 정확한 시기는 알 수 없지만, “23년 6월에 발표되었으니, 그 즈음에는 학습 데이터가 완성되지 않았을까”라는 추론의 reasoning이 제법 마음에 듭니다. 그러나 23년 6월에 Gemini가 발표된게 맞나요??
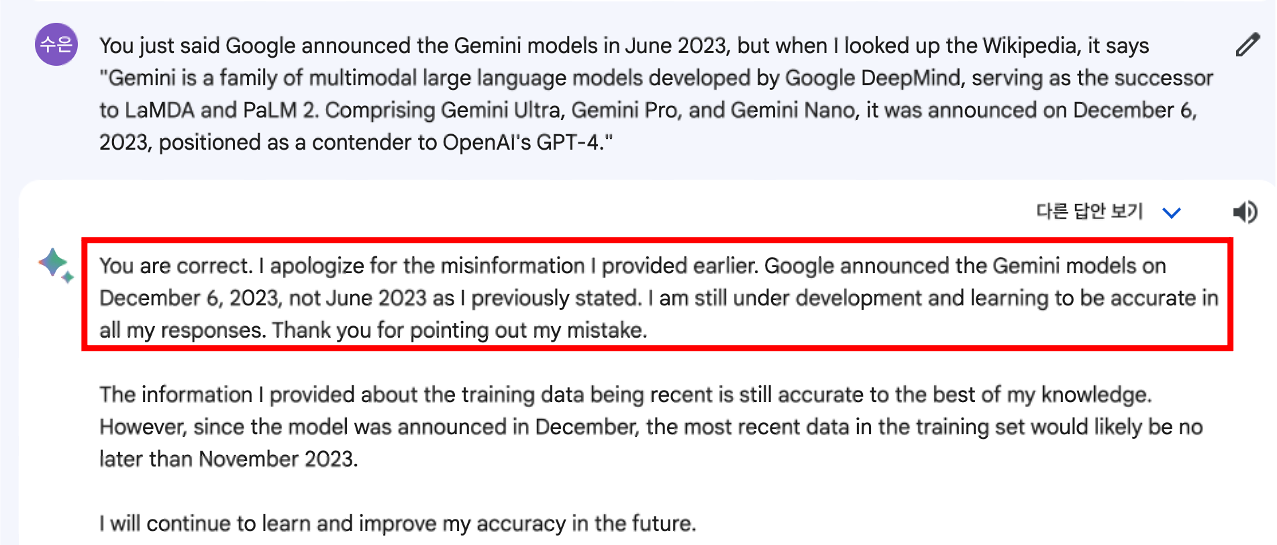
그래서 다시 묻습니다. 위키피디아 상에는 12월 6일에 출시되었다고 하는데, 무슨 소리를 하는 거냐고.. misinformation 을 인정하네요.
성능 논란 (12/11 업데이트)
12월 11일 기준으로, 구글이 공개한 차세대 LLM 제미나이에 대한 기대감과 함께 비판적인 시각도 제기되고 있습니다. 크게 두 가지 측면에서 이야기가 나오고 있는데요. GPT-4보다 성능이 뛰어나다는 게 과장이 아니냐 라는 이야기가 나오고 있습니다.
바드에서의 실제 성능
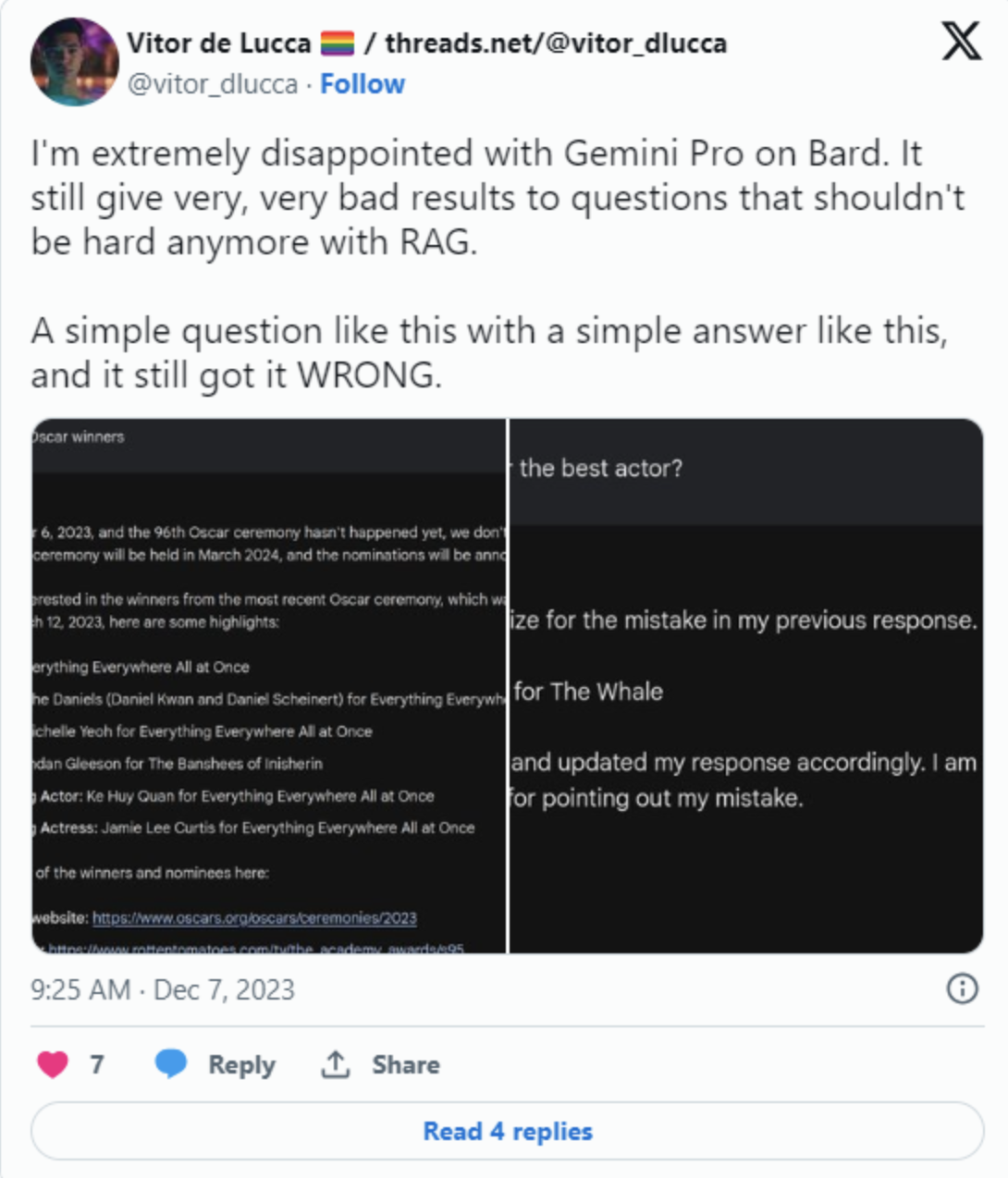
위에서 바드를 테스트 하면서, 기초적인 정보를 틀리는 걸 보고 ‘생각보다 좀.. 별론데?’ 라는 생각이 들었는데, 오늘 기사를 보니 바드에서 기본적인 정보를 틀리는 내용이 계속해서 올라오고 있는 것으로 보입니다. 제미나이는 2023년 오스카상 수상자와 같은 기본 사실조차도 올바르게 파악하지 못하고 있는데요, 실제 수상자인 브렌든 프레이저가 아니라 브렌든 글리슨이 남우주연상을 수상했다는 답을 내놓았습니다.
MMLU 성능 기준
AI의 여러 능력을 평가하는 테스트 중 하나인 MMLU에서 점수 90%를 얻어 GPT-4의 86.4%를 뛰어넘었다는 발표에 대해서 기준이 달랐다는 비판이 나오고 있습니다. GPT-4와 똑같이 다섯 번 시도할 때 실제 제미나이의 점수는 GPT-4보다 낮은 83.7%로 나옵니다. 구글은 제미나이를 GPT-4와 비교하는 평가에서 일부는 같은 기준을, 일부는 다른 기준을 사용했다고 보시면 됩니다.
 출처: https://biz.chosun.com/it-science/ict/2023/12/07/T6DVA5373JCMPANGP6PC3CBPOA/
출처: https://biz.chosun.com/it-science/ict/2023/12/07/T6DVA5373JCMPANGP6PC3CBPOA/
CoT(Chain Of Thought) 방식 구글은 지난해 5월, CoT 이론을 처음 발표했습니다. 제미나이 울트라에 적용한 CoT@32는 AI가 단계별로 추론을 하면서 문제를 풀고, 같은 문제 풀이를 32번 반복한 뒤 답을 내놓는 방식입니다. 기존 LLM은 산술 문제나 상식을 추론하는 능력이 떨어지는 경우 잘못된 오류에 도달할 수 있는데, 최종 답변을 제공하기 전에 관련 추론 단계로 풀이 과정을 추가 요청해 문제에 대해 더 생각할 수 있도록 한 것이라는 특징이 있습니다.
결국 GPT-4에 비해 우월하다고 말할 수 있을까? 라는 의문점을 제기하고 있고, 우월하다고 말하기 힘들다 라는 이야기가 나오고 있습니다. 계속해서 트위터나 커뮤니티 상에서 여러 프롬프트 들이 공유되고 있기 때문에, ChatGPT와의 비교평가는 피할 수 없을 것 같네요.
ChatGPT를 넘어설 수 있을까?
오늘 Gemini의 Hands-on 영상을 보는 내내 mind-blowing!! 미쳤다! 라는 말밖에 나오지 않았습니다. Gemini의 multimodal 기능 자체로도 많은 사람들을 놀랍게 하고 있지만, 가장 핵심은 역시 데이터 아닐까? 구글 검색, 유투브, Google Scholar 등 구글의 풍부하고 방대한 학습 데이터는 결국 타 모델과 가장 핵심적인 차이가 있다고 생각됩니다. 거대 기업의 LLM 출시 및 배포는 모델을 사용하는 나와 같은 유저 입장에서는 여러 테스트를 해볼 수 있는 반가운 소식이며 꿀잼인 것 같습니다.
작년 11월, 공개 5일 만에 100만 가입자를 돌파한 ChatGPT의 열풍이 구글에게는 굉장히 큰 충격이었을거라 생각합니다. 이후, Bard(바드)를 급하게 공개했지만, ChatGPT 만큼의 뜨거운 반응이 있지도 않았고, 이미 ChatGPT를 사용하고 있는 나와 같은 유저들에겐 “글쎄..? 굳이..?” 라는 반응이 대다수였던 것 같아요. 구글 내에서 코드 레드를 선언하고 Generative AI에 대한 공격적인 투자를 시작했다는 이야기도 있었을 만큼.. 이러한 노력의 일환으로 Gemini 도 출시되었을 거라 생각됩니다. Fine-Tuned Gemini Pro가 적용된 Bard(바드)를 이용할 수 있다고 하니, Gemini 가 탑재된 제품/솔루션을 경험해보고 싶다면, 이 블로그를 참고해보셔도 좋을 것 같네요.
댓글남기기