[딥러닝/AI] ChatGPT & Whisper 를 코랩에서 사용해보자 (쏘심플!)
ChatGPT로 연일 핫한 OpenAI 의 API를 구글 코랩에서 쉽게 사용해서 ChatGPT 와 Whisper 모델을 한 번 체험해보자!
OpenAI 의 API 사용법에 대해 간단히 알아보고, ChatGPT 와 Whisper API 사용을 위한 prompt 를 코랩에서 작성해보자
ChatGPT 해 대해 궁금하다면 지난 포스팅 을 참고해주세요~
0. OpenAI API KEY 받기
OpenAI 에서 제공하는 API 를 사용하기 위해서는 패키지 설치와 API Key 가 우선 필요하다
OpenAI에서 회원가입을 하면 3개월 안에 사용할 수 있는 크레딧 $18 를 받을 수 있다.
API Pricing 에 대한 자세한 내용은 여기를 참고~!!
- 아래 링크 누르고 sign up 후 sign in 하기
- MyPage 에 들어가면
API Keys를 클릭해보자.
Create new secret key 를 누르면 API Key generated 라고 표시되고 파란색 블록 부분이 나의 API key 이다.
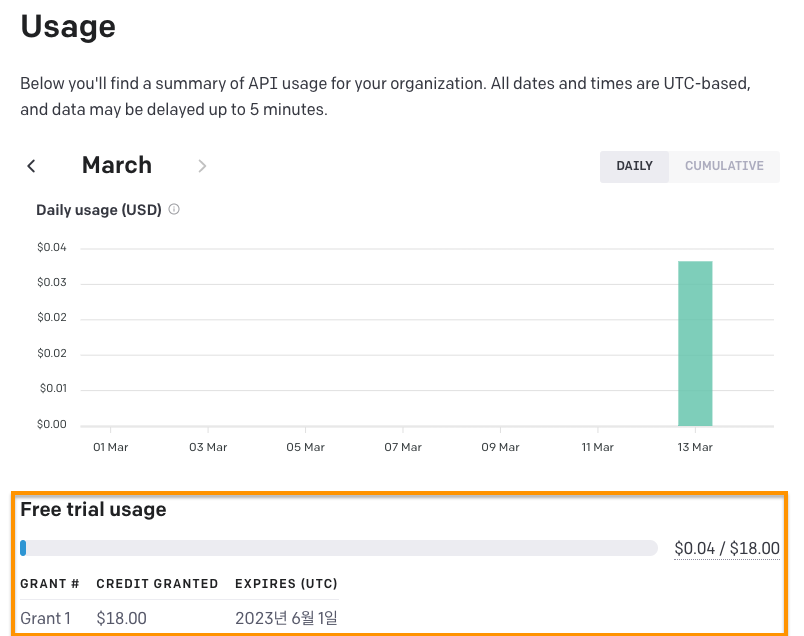
API 사용량 도 아래와 같이 확인할 수 있다. $18 Credit 중 얼마나 썼는지도 바로 확인 가능하다.
1. OpenAI 설치
!pip install --upgrade openai
API_KEY 입력
OPENAI_API_KEY 에 나의 API KEY 를 입력하면 된다
OPENAI_API_KEY = '...lbkFJ1M9Tj...'
import openai
openai.api_key = OPENAI_API_KEY
completion = openai.Completion()
아래는 사용 가능한 모델들의 리스트이다 – gpt-3.5-turbo도 있는 걸 확인할 수 있다
참고로 ChatGPT는 GPT-3.5를 2022년 초에 fine-tuned 한 모델이라고 보면 된다고 OpenAI 블로그에 나와있다.
openai.Model.list()
- prompt 는 아래 형식이 기본이고 보통 text classification, sentiment analysis, text editting 과 같은 부분은 아래와 같은 함수를 사용하고,
Chatcompletion이라고 별도로 있는데, 이게 소위 말하는 ChatGPT 의 API 라고 보면 될 것 같다 – 이메일이나 작문을 해주거나, 파이썬 코드를 써주고, 역할을 주어주면 대화가 가능한 agents 를 만들어주는 생성 을 해 준다. 우선 아래는 우리가 소위 ChatGPT의 생성 부분은 아니고, 전신 모델인 davinchi 모델의 basic use 라고 보면 되겠다 (사실 basic use 라고 하지만, 너무나 훌륭.. )
각 API method 에 대한 자세한 설명을 보고 싶다면 official doc 참고 바란다.
response = completion.create(
model="text-davinci-003",
prompt = "Decide whether a Tweet's sentiment is positive, neutral, or negative, and scale it 0 to 10. \n\nTweet: \"I loved the new Batman movie!\"\nSentiment:",
temperature=0, # default는 1.0 이며 0~2 사이 설정. 0에 가까울수록 정제된 문장, 높은 수에 가까울수록 창의적이고 random한 문장
max_tokens=64, # 대부분의 모델들은 최대 2048 token 까지 지원하나, 최신 모델은 4096 토큰까지 지원 가능
top_p=1.0, # 모델이 사용할 토큰에 대한 threshold 라고 보면 된다. temperature 의 대안. 둘 중 하나만 조정하기를 추천.
presence_penalty=0.0, # 특정 단어나 phrase 를 포함하지 않도록. -2~2 까지 조정 가능한테, 2에 가까울수록 penalty 가 커진다
frequency_penalty=0.0 # 반복적이지 않은 텍스트를 생성하도록 유도. 반복되며 penalty 부여되며 2에 가까울수록 penalty 가 커진다
)
prompt 를 보내면 OpenAI API 예측값을 아래 response 처럼 얻을 수 있다.
print(response)
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " Positive, 10"
}
],
"created": 1678685517,
"id": "cmpl-6tV4n8fx4umxG5e9qPg2sVdT4xV7x",
"model": "text-davinci-003",
"object": "text_completion",
"usage": {
"completion_tokens": 3,
"prompt_tokens": 39,
"total_tokens": 42
}
}
print(response['choices'][0]['text'])
Positive, 10
함수로 감싼다면?
def question(prompt):
openai.api_key = OPENAI_API_KEY
response = openai.Completion.create(
model="text-davinci-003",
prompt= f"{prompt} ?" ,
temperature=0.7,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
answer = response["choices"][0]["text"]
return answer
prompt = "Who is the president of France?"
AI_answer = question(prompt)
print(AI_answer)
The president of France is Emmanuel Macron.
2. ChatGPT API 로 Q&A 질문 던져 보기
-
ChatGPT 는
gpt-3.5-turbo에 기초한 모델이며, 위에서 언급했듯 이 모델은 이메일/글 작문, Q&A answering, 코드 작성 등 생성 application 을 만들 수 있게 되어 있다. Chat 모델은 여러 메세지들을 input 으로 받고, model-generated message 를 output 으로 리턴한다. -
gpt-3.5-turbo를 사용하면 가장 안정화된 모델로 제공 받을 거고, 만약gpt-3.5-turbo-0301과 같은 specific version 을 사용할 수도 있다. -
모델 업데이트에 관한 내용은 여기서 자세히 확인할 수 있다.
Fine Tuning 도 가능한다고 하니,
gpt-3를 fine-tuning 해보고 싶다면, fine-tuning guide 를 보면 될 것 같다..!GPT 3.5는 현재 fine-tuning 은 제공되지 않으며,davinci,curie,babbage,ada모델들은 가능하다
ChatCompletion aka ChatGPT API 호출하기
- input에는 크게 model 과 messages 가 들어가는데, messages 는 role과 content로 구성되어 있다.
role:system,user,assistant중 선택 가능content: 메세지 내용
message의content에 대화 히스토리가 자세히 포함되어 있을수록, desired behavior 에 대한 힌트를 좀더 주는 셈이므로, 사용자(developer) 입장에서 문맥 이해를 돕기 위한 대화 히스토리를 최대한 자세히 주는 것이 원하는 행동양식&답변을 얻을 확률이 높아진다고 생각된다.
system의 message가 이 가장 첫 대화에 시작되는데,assistant의 행동을 셋팅한다고보면 된다.user의 message 가assistant에게 궁극적으로 물어보는 Question 인 셈.assitant의 message 도 미리 주어줄 수 있는데, 쉽게 말해서 이전 대화(prior responses)에 대한 답변을 어떻게 했는지 알려주는 거라고 보면 된다.
# API KEY는 위에서 주었기 때문에, 바로 사용해보기
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
print(response['choices'][0]['message']['content'])
The 2020 World Series was played at Globe Life Field in Arlington, Texas.
최근 ChatGPT 의 그럴듯한 정확하지 않은 답변으로 논란이 많다.
정확도가 높은 답변을 원한다면, 초기에 셋팅되는 system 메세지에 좀더 specific 하게 instruction 을 주는 것을 추천한다고 한다.
21년도 데이터까지로 훈련되었기 때문에, 최근 정보에 대한 신뢰성은 확보될 수 없다는 점 참고..! 최근에 Twitter CEO가 Elon Musk 였다는 내용을 답변하는 ChatGPT 의 모습이 보이면서 추가적으로 training 이 된 것이 아니냐는 이야기도 있던데..!?
3. Whisper API 도 써보자!
Whisper 는 speech-to-text model 로 Transcribe 과 Translate(takes supported languages into English) 이 가능하다.
마찬가지로 사용법은 너무 간단하다
3-1. Transcribe 해보기
- 먼저 audio 샘플 파일을 다운로드 받자. Ted Talk : Try something new for 30 days 라는 Short Talk 을 Ted Talk 웹사이트에서 다운로드 받고, Colab에
MattCutts_2011U.mp3라는 파일로 업로드 했다.
위에서 API KEY 를 다 주었기 때문에, 아래와 같이 간단하게 함수 호출만 해서 적용해주면 된다. 쏘 심플!
audio_file= open("/content/MattCutts_2011U.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
transcript["text"]
"Ted Talks are recorded live at the TED Conference. This episode features engineer Matt Cutts. This talk contains powerful visuals. Download the video at TED.com. Here's Matt Cutts. A few years ago, I felt like I was stuck in a rut. So I decided to follow in the footsteps of the great American philosopher, Morgan Spurlock, and try something new for 30 days. The idea is actually pretty simple. Think about something you've always wanted to add to your life and try it for the next 30 days. It turns out, 30 days is just about the right amount of time to add a new habit or subtract a habit, like watching the news, from your life. There's a few things that I learned while doing these 30-day challenges. The first was, instead of the months flying by, forgotten, the time was much more memorable. This was part of a challenge I did to take a picture every day for a month. And I remember exactly where I was and what I was doing that day. I also noticed that as I started to do more and harder 30-day challenges, my self-confidence grew. I went from desk-dwelling computer nerd to the kind of guy who bikes to work, for fun. Even last year, I ended up hiking up Mount Kilimanjaro, the highest mountain in Africa. I would never have been that adventurous before I started my 30-day challenges. I also figured out that if you really want something badly enough, you can do anything for 30 days. Have you ever wanted to write a novel? Every November, tens of thousands of people try to write their own 50,000-word novel from scratch in 30 days. It turns out, all you have to do is write 1,667 words a day for a month. So I did. By the way, the secret is not to go to sleep until you've written your words for the day. You might be sleep-deprived, but you'll finish your novel. Now, is my book the next great American novel? No! I wrote it in a month! It's awful! But for the rest of my life, if I meet John Hodgman at a TED party, I don't have to say, I'm a computer scientist. No, no. If I want to, I can say, I'm a novelist. So here's one last thing I'd like to mention. I learned that when I made small, sustainable changes, things I could keep doing, they were more likely to stick. There's nothing wrong with big, crazy challenges. In fact, they're a ton of fun, but they're less likely to stick. When I gave up sugar for 30 days, day 31 looked like this. So here's my question to you. What are you waiting for? I guarantee you the next 30 days are going to pass, whether you like it or not. So why not think about something you have always wanted to try, and give it a shot for the next 30 days? Thanks. That was Matt Cutts, recorded at TED 2011 in Long Beach, California, March 2011. For more information on TED, visit TED.com."
3-2. Translate
한글 음성 파일을 영어로 번역해보자. 한글 음성 파일을 input 으로 주었을 때, 영어로 translated 되어 리턴하는 것을 볼 수 있다.
audio_file_korean = open("/content/샘플 오디오 파일.mp3", "rb")
translated = openai.Audio.translate("whisper-1", audio_file_korean)
translated["text"]
"I prefer people who are in need. I want to make a lot of money. Because I was really poor. I think that's really good. People who have only experienced failure. People who have worked in a company once, but they have not succeeded in the first time. I don't think anyone is thirsty for the first success. The reason I started the business is How honest and close to my essence. Is it closer to my nature? Because that's how much motivation There is no basis to judge whether it will last long. What can you see that this person will work hard for 10 years? This person has a noble and grand vision. If you meet a lot of ordinary people in the middle, It can be gone soon. If there is something like the most essential and most realistic deficiency I think it's a very good energy source. I think it's an energy source that can not be exhausted. I tend to ask if there are such things."
써보니 어떤가?! 나의 간단 사용 후기
- 우선 API 를 사용하기 쉽게 잘 만들어 놓았다는 생각이 든다. 함수만 바꾸면 기능이 조금씩 달라지게끔 해놓았기 때문에, prompt 를 한 번 익히면, 직관적이고 큰 무리 없이 원하는 기능으로 사용할 수 있는 것 같다.
- gpt 3.5 turbo 의 경우 굉장히 저렴하게 나왔다고 알고 있는데, pricing 을 다른 플랫폼들과 비교해보지는 않았지만, OpenAI 의 마이페이지에서 나의 사용량을 확인할 수 있는
usage인터페이스가 있고, API 상에서도 확인할 수 있다. quick 하게 돌려볼 때 유용할듯.
Reference
- https://platform.openai.com/docs/guides/chat/introduction
- https://platform.openai.com/docs/guides/fine-tuning
- https://openai.com/blog/introducing-chatgpt-and-whisper-apis
- https://github.com/openai/openai-cookbook/
댓글남기기