[Data Augmentation] 마땅한 데이터가 없다면 어떻게 데이터를 늘릴 수 있을까?
대상 독자
-
머신러닝이나 딥러닝 모델링에 대한 기초적인 지식이나 입문 정도의 경험이 있는 분
-
기본적인 파이썬 문법이나 코드를 이해할 수 있거나, 초급 수준의 데이터 분석 프로젝트를 경험해본 분
-
양질의 데이터를 확보하기 어려워서 난감했던 경험이 있는 분 (공감하실 분들이라 많을거라 믿습니다 🥲)
0. 들어가며
데이터 분석 및 모델링을 할 때 프로젝트 방향이나 내가 원하는 딱 알맞는 양질의 데이터를 찾는 데 어려움을 겪는 상황을 마주하게 됩니다. 모델을 충분히 학습 하는 데 필요한 데이터를 확보하는 대표적 기법 중 하나인 data augmentation 중에서도 텍스트 데이터에 관한 부분을 집중적으로 살펴보고자 합니다.
학습에 사용할 수 있는 충분한 양의 양질의 데이터 셋은 모델 학습의 성공적인 결과를 위한 필수 요소 중 하나입니다. 하지만 프로젝트 방향이나 내가 원하는, 딱 알맞는 양질의 데이터를 찾는 데 어려움을 겪는 상황을 마주하게 됩니다.
양질의 데이터를 확보하기 어려운 상황을 마주할 때, 대체할 수 있는 데이터 증강 기법을 소개하고, 그중에서도 텍스트 데이터 증강은 이미지와 달리 문법적 요소나 표현 변화 정도 등을 고려해야하는 어려움이 있지만 그에 관한 연구/기법들이 활발히 논의 되는 추세라고 생각되어 이야기 해보고 싶었습니다.
사실 이상적인 데이터 갯수는 몇개이다, 얼만큼이면 충분하다고 딱 잘라서 말하기는 사실 힘들다고 생각합니다. 현업에 계시는 분들의 경험과 기타 통계적인 방법으로, 또는 모델링의 성능을 지켜보며, 이 정도면 충분하다고 판단하는 것이 통상적인 방법이라고 이해하고 있습니다. 너무 많아도, 너무 적어도, 문제라고 하는 데이터 갯수 이지만, 현업 프로젝트를 해본 짧은 저의 경험에 비추어 보았을 때, 데이터가 부족해서 난감했던 경험이 훨씬 많았기 때문에 데이터 부족 이슈를 어떻게 해결할 수 있을까?에 초점을 맞추었습니다.
목차 구성은 아래와 같습니다
Data Augmentation 이란
1-1. 왜 필요할까?
1-2. 어디에 쓰이나
Text Data Augmentation
2-1. EDA (Easy Data Augmentation Techniques for Boosting Performance)
2-2. Back Translation
Augmentation Tool/Libraries 소개
논문에서 이해하고 코드로 간단히 적용해보는 나만의 Augmentation
Reference
1.Data Augmentation 이란?
Data augmentation 은 기존 데이터에 데이터 변형이나 생성 등 다양한 알고리즘을 적용시켜 데이터 양을 늘리는 기술입니다.
1-1. 왜 필요할까?
머신 러닝, 특히 딥러닝 기술은 비전, NLP 등 다양한 분야로 빠르게 확장되고 있습니다. 현실 문제를 해결하기 위해, 머신러닝 및 딥러닝을 활용하는 경우, 데이터가 부족한 상황을 마주하게 됩니다.
데이터를 충분히 확보하지 않은 채 모델을 학습하게 되면? 간단합니다. 성능이 좋지 않습니다. 변수를 충분히 훈련시킬 데이터가 없으면, 훈련 데이터에만 너무 치중되어 학습한 모델이 테스트 데이터에 제대로 성능을 내지 못하는 과적합(overfitting)이 쉽게 발생합니다. 다시 말해, 충분한 데이터가 있다면, 훈련 데이터와 테스트 데이터에 모두 적절히 반응하여 성능이 향상될 겁니다.
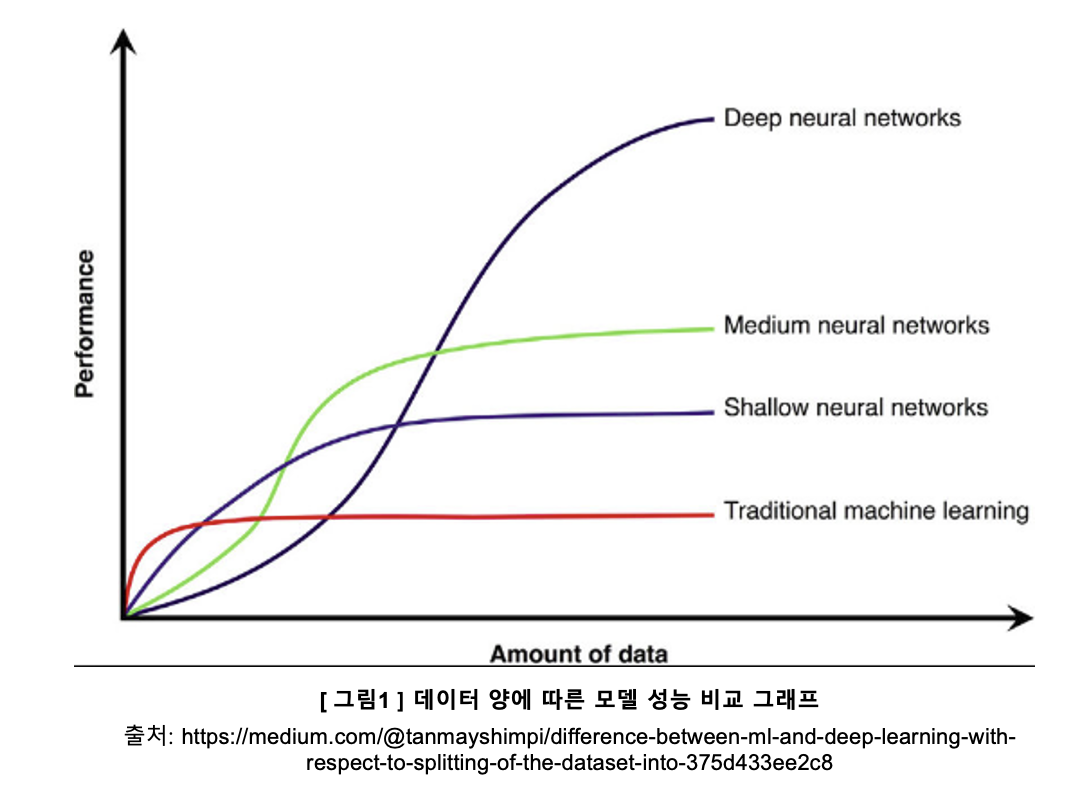
데이터 양이 증가함에 따라 기존 전통적인 머신 러닝과 딥러닝의 성능 차이는 가파르게 벌어집니다. 다시 말해, 딥러닝은 많은 양의 데이터를 필요로 하고 데이터가 너무 적으면 그 알고리즘이 제대로 성능을 보여주지 못한다는 뜻이기도 하죠.
왜 딥러닝은 많은 양의 데이터가 필요하지? 에 대해 간단히 살펴보면, 머신러닝은 도메인 및 현업 전문가들이 대부분의 변수들을 먼저 살펴보고 최적의 가중치를 찾아 적용한 후에 알고리즘을 적용하는 것이 일반적입니다.
하지만 딥러닝의 경우, 알고리즘 자체가 데이터로부터 고수준의 특징들(high-level features)을 찾아가기 때문에, 사람이 데이터로부터 변수들을 살펴볼 필요가 없습니다.
두 기법의 차이는 이렇게 간단하게만 살펴보고, 다시 우리 이슈인 ‘데이터 부족’에 돌아오겠습니다.
자 우선, 데이터가 부족하면 괜찮은 모델 성능이 나오기 쉽지 않다는 점은 이해했습니다. 그러면 “데이터를 구하면 되지 않나요?” 라고 생각할 수 있을 것 같아요. 🧐 이번엔 데이터 확보 측면에서 생각해보도록 하죠.
양질의 데이터를 수집하고 라벨링하는 과정이 공수가 많이 들고 그에 따른 비용까지 생각해보면, 정말 난감할 때가 많습니다. 또한, 데이터 종류에 따라서는 쉽게 확보할 수 없는 데이터도 있습니다.
예를 들어볼까요? 제조 산업의 배터리 불량 검출 프로젝트를 진행한다 했을 때, 이미지 분류 모델을 만들기 위해서는 배터리 이미지 데이터와 정상/불량에 대한 정보가 있는 라벨링 데이터가 꼭 필요합니다. 하지만 회사의 영업이익과 기밀의 이유로 현업 제조사의 데이터를 구하기 어려울 뿐더러, 친절하게(?) 모델링을 위해 라벨링까지 되어 있는 데이터를 확보하는 데에는 어려움이 있습니다.
이렇듯.. 부족한 데이터로 모델링을 진행해도 안되고, 정말 괜찮은 데이터를 확보하기도 어려운 상황이면.. 어쩌란 말이냐!? 라는 생각이 들 수 있습니다(왜냐하면 저도 그랬거든요..).
Data augmentation 은 기존에 부족한 데이터 어떤 변화를 가해서, 다양한 예제의 양질의 학습 데이터를 생성함으로써 위 문제를 해결하는 기법입니다. 단순히 부족했던 데이터 양을 늘리는 것 이상의 의미가 있습니다. 예를 들어, 분류 문제의 경우, 데이터의 클래스 분포 차이가 큰 상황을 뜻하는 클래스별 불균형을 해결할 수도 있고, 좀더 다양한 학습 데이터를 확보하니 머신 러닝 모델의 성능 또한 향상됩니다.
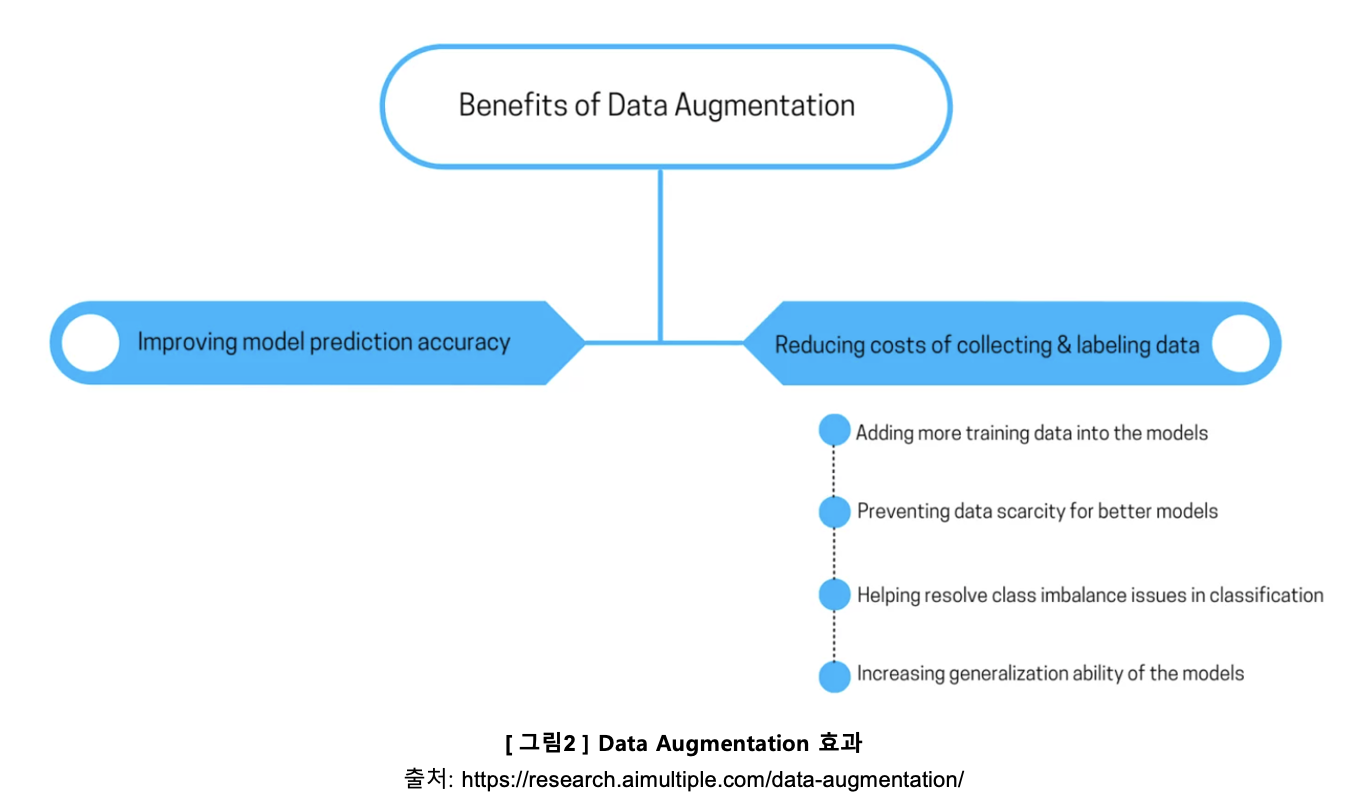
1-2. 어디에 쓰이나?
Data augmentation 은 특히 비전 분야에서 활발히 적용되며 쉽게 찾을 수 있습니다.
잘 알려진 COCO, CIFAR, ImageNet 과 같은 데이터셋이나 Kaggle, Github 과 같은 오픈소스를 활용해도 좋겠지만(사실 이상적이죠 😅), 내가 찾고 있는 이미지가 없는 경우나 데이터 수가 너무 적은 경우에 따라 data augmentation 기법이 사용되고 있습니다.
이미지 data augmentation 라이브러리들에는 이미지 회전, 블러처리, 좌우상하 반전, 확대, 왜곡 등 다양한 함수들이 기본적으로 제공되고 있습니다.

가장 대표적으로 알려진 라이브러리는 Keras에서 제공하는 ImageDataGenerator 클래스 입니다.
MXNet에서도 이와 비슷한 Augmenter 클래스를 제공하고, 더 나아가 imgaug 라이브러리는 60가지가 넘는 다양한 데이터 변형 함수들과 augmentation pipeline, 그리고 시각화 함수까지 함께 제공합니다.

워낙 유명한 라이브러리들이다 보니, 한국어로 된 관련 블로그도 쉽게 찾을 수 있고, 튜토리얼이나 README 가 친절하게 되어있기 때문에 패키지 설치부터 이미지를 불러와 여러 augmentation 테크닉들을 적용하는 과정이 다행히 어려워 보이지는 않습니다.
그렇다면.. 텍스트 데이터는 어떨까요? 이미지는 꽤 직관적이었는데.. NLP 에서는 data augmentation을 사용할 수 있는지?
어떻게 활용되는지 다음 챕터에서 살펴보겠습니다!
작은 데이터셋으로 설계하는 이미지 분류 모델에 관심이 있으시다면 이 블로그를 참조하셔도 좋을 것 같아요
2. Text Data Augmentation 기법
비전 쪽에서 data augmentation이 활발히 활용되는 반면, NLP 분야에서는 활용하기 쉽지 않다고 평가받는 이유가 뭘까요?
이미지는 확대, 좌우 또는 아래위로 뒤집는 반전 등 간단한 변형이 적용될 수 있지만, 텍스트의 경우, 단어 하나만 바뀌어도 문장의 의미나 label 이 달라질 수 있기 때문입니다.
텍스트 데이터를 변형/생성하는 대표적인 기법들로는 텍스트 편집/수정/제거와 역번역 이 있습니다.
하나씩 찬찬히 살펴볼까요?
2-1. EDA(Easy Data Augmentation Techniques for Boosting Performance)
EDA 를 딱 보는 순간 탐색적 데이터 분석기법이라는 뜻이 가장 먼저 떠오르지 않으셨나요? (저는 개인적으로 그랬습니다..ㅎㅎ)
EDA 논문은 간단히 텍스트를 편집하는 변화를 주어 데이터를 효과적으로 증가시키는 방법을 제시하고 있습니다.
텍스트 편집 기법들은 다음과 같습니다.
- Synonym Replacement: 임의로 선정한 불용어가 아닌 단어를 의미가 비슷한 유의어로 대체
- Random Insertion: 불용어가 아닌 임의의 단어를 무작위로 삽입
- Random Swap: 한 문장 안에서 임의로 선정한 두 개의 단어의 위치를 서로 바꿈
- Random Deletion: 임의의 단어를 제거
이렇게 정의로만 보면 와닿지가 않을 수 있으니 예시와 함께 보도록 하죠!
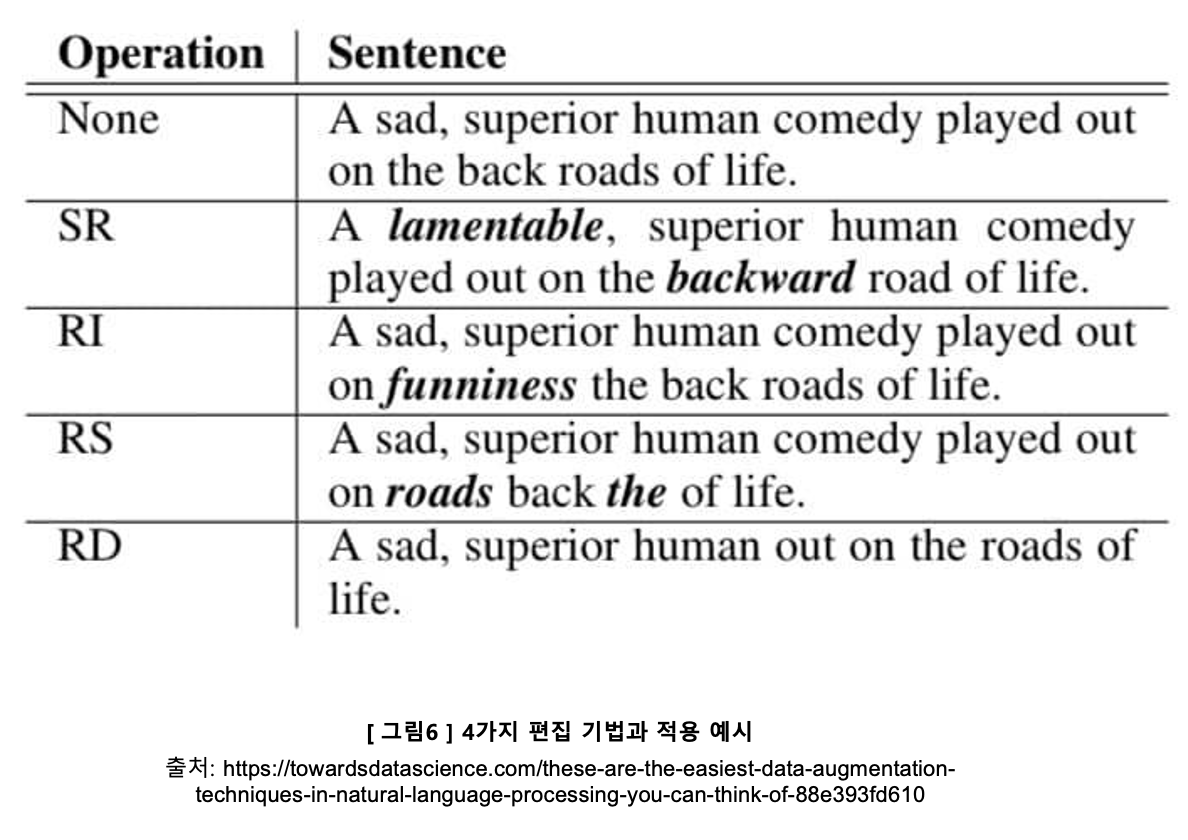
영어라 예제를 보아도 한눈에 들어오지 않을 수 있을 것 같아요..! 한국어가 편한 저를 위해서라도 한국어 예시를 아래 표에 만들어 두었어요 :)
이 논문에서는 이런 간단한 텍스트 변형을 통해 인위적으로 생성한 데이터를 추가적으로 학습할 때, 훈련 데이터의 50%만 사용하며 EDA 기법을 적용한 모델 성능과 훈련 데이터의 100%를 사용한 모델 성능이 같은 정확도를 달성했다는 점을 소개합니다. 임의로 선정된 단어들이 추가, 수정, 제거되며 문장에 변형을 주면서 만들어진 노이즈 가 데이터에 포함되며, 그에 따라 모델 학습 또한 좀더 robust 하게 되기 때문에, 특히 적은 데이터로 학습했던 경우에 훨씬 효과적이게 됩니다.
여기서 또 한가지 짚고 넘어가보죠.
단어들을 추가/수정/제거하여 문장을 다양하게 만들어 데이터셋을 확보하긴 했는데, 너무 노이즈가 과해서 원래 문장들의 뜻이 훼손된다면, 즉, original label과 다르다면, 데이터를 늘린 의미가 없을텐데.. 라는 걱정이 듭니다 😱
따라서 논문에서는 EDA 적용으로 새로 증강된 문장들의 label 을 훼손시키는지에 대한 부분을 확인하고 아래와 같이 그래프로 나타냈습니다.
확인 방법은 다음과 같습니다.
- Data augmentation 없이 NLP 분류 (Pro:긍정 / Con:부정) 과제에 대해 RNN으로 훈련합니다.
- 그 다음 테스트 셋에 EDA 를 적용하여 원본 문장 한 개당 9개의 증강된 문장을 생성합니다.
- 증강된 문장들과 원본 문장들을 함께 RNN에 넣어 마지막 dense layer 에서 결과물을 뽑아 t-SNE 를 적용해 2차원 그래프로 표현합니다.
t-SNE는 높은 차원의 복잡한 데이터를 2차원에 차원 축소하는 방법입니다. 비슷한 데이터 구조는 낮은 차원 공간에서 가깝게 대응하며, 비슷하지 않은 데이터 구조는 멀리 떨어져 대응됩니다.
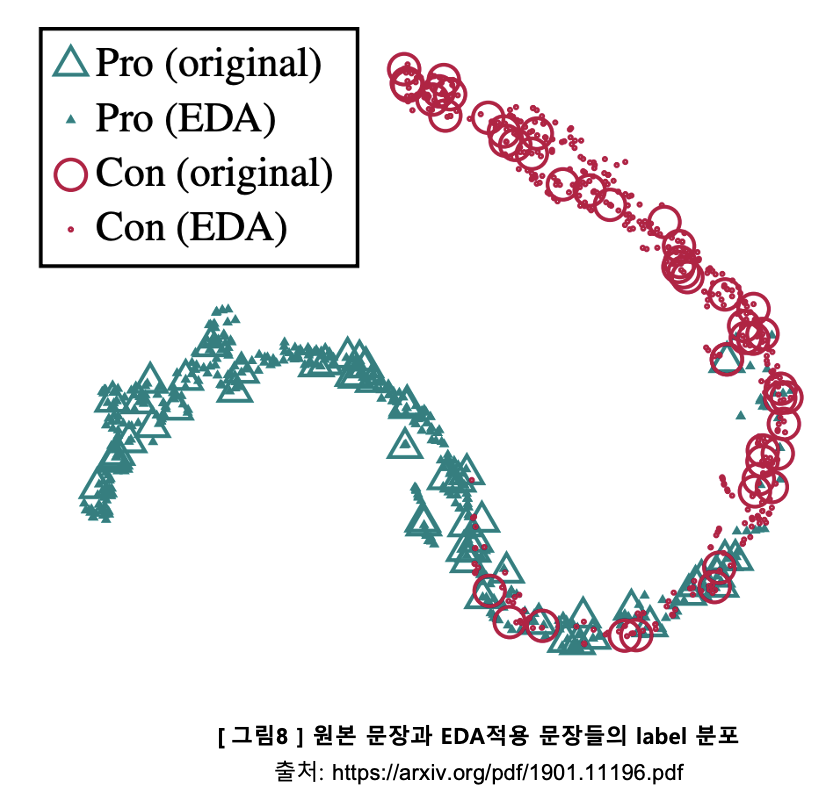
긍정 원본 문장과 긍정 증강된 문장들이 서로 가깝게 대응되고 있으며, 부정 원본 문장과 부정 증강된 문장들 또한 서로 가깝게 대응되고 있습니다.
정리해보면, 2차원의 잠재공간에 표현된 증강된 문장들이 원본 문장들의 공간 표현들을 매우 밀접하게 둘러싸고 있는 점을 통해, EDA를 적용하여 증강된 문장들이 대부분 원래 문장들의 label을 가지고 있다고 확인할 수 있습니다.
한국어로 활용할 수 있을까?
대다수의 논문과 라이브러리들이 영어를 바탕으로 나오기 때문에 문법이 다른 한국어에 활용할 수 있는지는 항상 고민해야할 부분인데요..!
korEDA 는 EDA기법을 한국어로 사용할 수 있도록 wordnet 부분을 교체한 프로젝트 입니다.

단어들이 대체되거나 추가되는 SR(유의어 대체)이나 RI(단어 삽입)는 상대적으로 안전한 data augmentation 기법이 될 수 있을 것 같습니다. 그에 반해 단어들의 위치가 바뀌거나 제거되는 경우 문장이 말이 되지 않거나 마무리가 되지 않네요.
프로젝트의 방향이나 모델링의 종류나 목적에 따라, 노이즈가 데이터가 얼마나 있나를 고민하며 이 기법들을 적절히 선택하여 활용할 수 있을 것 같습니다.
여기까지.. To-be Continuted
2-2. Back Translation(역번역)
Back Translation은 기존 텍스트를 외국어로 번역한 뒤 다시 기존의 언어로 번역하는 기법입니다.
3가지 단계로 나누어 살펴 볼게요
- Input 은
- 기존 input 텍스트를 번역합니다
- 2번 문장을 다시
영어로 사용할 수 있는 라이브러리가 있었지만, 한국어는 찾을 수 없었습니다.
두번째 논문(Understanding Back-Translation at Scale)은 번역기를 이용하여 데이터를 증가시킬수 있는 다양한 Sampling 방법에 대해 연구하고 번역기를 만들 때 Monolingual 데이터를 활용하는 방법을 제시합니다.
2-3.
세번째 논문(Data Augmentation using Pre-trained Transformer Models)은 Pre-trained 모델 3가지(BERT, GPT2, BART)를 이용하여 데이터를 증가시키고 감성분석 Task에서 Data Augmentation의 효과를 공유한다.
3. Augmentation Tool/Libraries 소개
4. 논문에서 이해하고 코드로 간단히 적용해보는 나만의 Augmentation
5. Reference
- https://research.aimultiple.com/data-augmentation/
- https://medium.com/@tanmayshimpi/difference-between-ml-and-deep-learning-with-respect-to-splitting-of-the-dataset-into-375d433ee2c8
- https://arxiv.org/pdf/1901.11196.pdf
- https://gaussian37.github.io/ml-concept-t_sne/
댓글남기기