[딥러닝/AI] 트위터 추천 알고리즘 오픈소스화 / Github 공개
트위터는 트윗 추천에 쓰이는 알고리즘 소스코드를 깃허브(GitHub)에 공개했다
트위터 추천 알고리즘 공개는 일론 머스크의 공약 사항이다. 머스크는 지난해 트위터 인수 과정에서 모든 이용자가 수긍할 수 있고 이용자 스스로 추천 로직을 직접 활용할 수 있도록 소스 코드를 공개할 것이라고 밝힌 적이 있다.
머스크는 트위터 추천 알고리즘 공개에 관해 “초기 버전이 다소 부끄러울 수 있지만, 우리는 실수를 빠르게 수정할 것이고, 사용자 의견을 받아 개선할 수 있도록 희망한다”고 밝혔다.
다만, 공개된 소스 코드는 트위터가 개인 피드에서 트윗을 어떻게 표시하는지에 대한 것 이며, 서비스 전체에 적용되는 검색 알고리즘의 기본 코드나 트위터의 다른 부분에서 콘텐츠가 어떻게 표시되는지에 대한 기본 코드를 공개하지 않았다.
아래 내용은 트위터 블로그의 내용을 해석한 내용이다.
How Do They Choose Tweets?
하루 약 5억 개의 트윗을 추천 알고리즘을 통해 상위 트윗 몇 개를 선별해서 For You timeline 에 보이도록 구성되어 있다.
트위터 추천 시스템은 트윗, 사용자 및 참여 데이터(engagement data)에서 잠재 정보를 추출하는 핵심 모델과 기능 집합을 기반 으로 한다.
이러한 모델들은 "미래에 다른 사용자와 상호 작용할 확률은 얼마나 되는가?" 또는 "트위터 상의 커뮤니티는 무엇이고 그 안에서 인기 있는 트윗은 무엇인가?" 와 같은 중요한 질문에 대답하는 것이 목적이다. 이런 질문에 정확하게 대답한다면 트위터는 더 관련성 있는 추천을 제공할 수 있다고 볼 수 있겠다.
추천 시스템은 세 가지 주요 단계로 파이프라인이 구성 되어 있고, Candidate Sourcing -> Rank -> Filtering 순으로 진행된다.
- candidate sourcing : 각각 다른 추천 소스에서 최고의 트윗을 가져오는 후보 소싱
- Rank : 머신 러닝 모델을 통해 각 트윗 순위 매기기
- Hueristics & Filters 적용 : 차단한 사용자의 트윗, 선정적인 콘텐츠, 이미 본 트윗 등 필터링
전반적인 FLOW 는 아래 다이어그램과 같다.
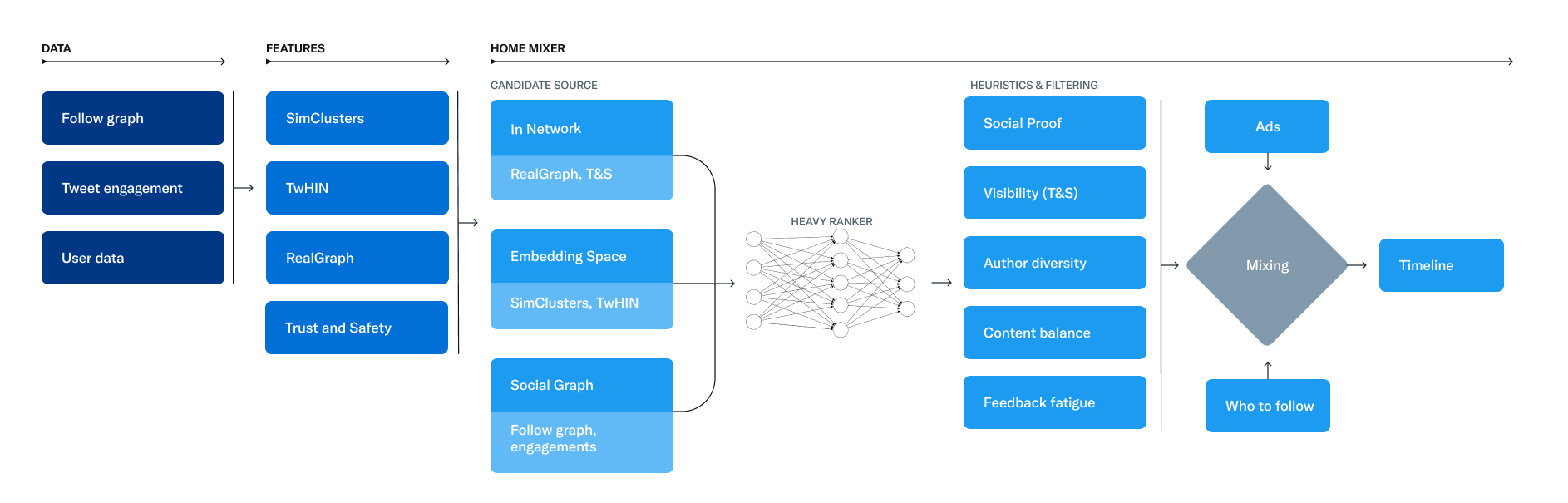
Candidate Sourcing (후보 소싱)
여러 후보 소스들로부터 최신의, 관계성이 높은 트윗을 추출해서 베스트 1500 개의 트윗을 추출 한다.
팔로우 하는 사람들(In-Network)과 팔로우 하지 않는 사람들(Out-Network) 로부터 후보를 찾는데, 사용자 마다 조금씩 차이가 있을 수 있지만, 평균적으로 추천 알고리즘은 In-Network 50%, Out-Network 50% 으로 구성되어 있다
In-Network 소스
가장 큰 후보 소스인 In-Network 소스는 팔로우 하는 사용자들의 가장 관련성이 높은 최신 트윗을 전달하려 한다. 로지스틱 회귀 모델을 사용해서 팔로우 하는 사람들의 트윗을 관련성에 따라 효율적으로 순위를 매긴다. In-Network 의 가장 중요한 구성 요소는 Real Graph 인데, Real Graph 는 두 사용자 간의 참여율을 예측하는 모델 이다.
당신과 트윗의 저자 간 Real Graph 스코어가 높을수록, 추천 알고리즘이 둘의 트윗을 더 많이 포함시킬 것 이다.
Out-Network 소스
사용자의 외부 네트워크에서 관련성 있는 트윗을 찾는 것은 더 까다로운 문제이다.
Social Graph
첫 번째 접근법은 팔로우하는 사람들이나 비슷한 관심사를 가진 사람들의 참여를 분석함으로써 관련성 있는 것으로 생각할 만한 것들을 추정하는 방법이다.
- "내가 팔로우하는 사람들이 최근 어떤 트윗들에 참여했는지?"
- "나와 비슷한 트윗들을 좋아하는 사람들은 누구이며, 그들이 최근에 좋아했던 다른 것들은 무엇인지?"
위와 같은 질문에 대한 답변을 바탕으로 후보 트윗들을 생성하고 로지스틱 회귀 모델을 사용하여 결과 트윗들의 순위를 매긴다. 이러한 유형의 그래프 순회는 외부 네트워크 추천에 _필수적_이며, 사용자와 트윗 간의 실시간 상호 작용 그래프를 유지하는 그래프 처리 엔진인 GraphJet을 개발해 사용한다.
Embedding Spaces
임베딩 공간 접근법은 내 관심사와 비슷한 트윗과 사용자가 무엇인지에 대한 일반적인 질문에 대한 답을 얻으려 한다.
트위터의 가장 유용한 임베딩 공간 중 하나인 SimClusters 는 custom matrix factorization algorithm 을 사용해서 영향력 있는 사용자들의 클러스터에 기반한 커뮤니티를 찾아낸다. 145k 개의 커뮤니티가 있으며, 3주마다 업데이트 된다. 사용자와 트윗은 커뮤니티 공간에서 표현되며, 여러 커뮤니티에 속할 수 있다. 아래 그림은 큰 커뮤니티 예시들이다.
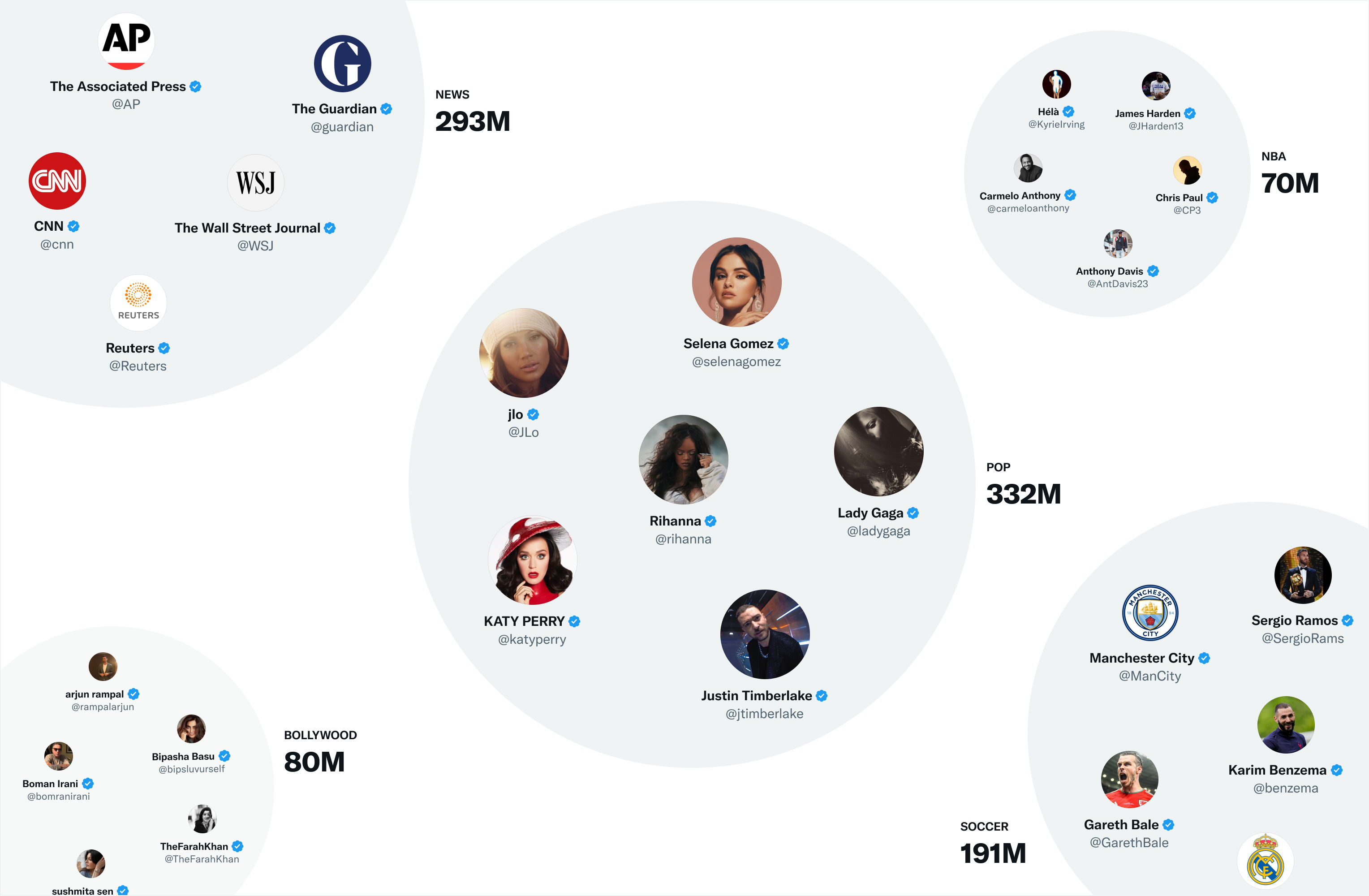
이러한 커뮤니티에 트윗을 포함시키는 방법은 각 커뮤니티에서 트윗의 현재 인기도를 살펴보는 건데, 커뮤니티의 사용자들이 트윗을 좋아할수록 해당 트윗은 그 커뮤니티와 관련이 더 많이 된다.
커뮤니티를 찾는 solution이 Sparse Binary Factorization 이라고 하는데, 우선 실행 속도가 매우 빨라 500,000 개의 커뮤니티를 발견하는 데 적합하다고 한다.
Sparse Binary 라고 하면.. => 0 or 1 로만 구성되어 있는 Matrix 라고 보면 되나? -> sparse 의 장점이 속도가 빠르다는 점이기 때문에, 결국 위 이야기가 연결되는 걸까
Ranking
후보 소싱을 마친 이 시점의 파이프라인에는 약 ~1500 정도의 후보자가 있을 텐데, 이 중 관련성을 직접 예측한다.
랭킹은 약 4800만 개의 파라미터 신경망으로 트윗 상호관계를 학습한 후 긍정적 참여(좋아요, 리트윗 등) 을 위한 최적화 라고 보면 된다. 이 랭킹 메커니즘은 수천 개의 피처를 고려해 10개의 라벨을 output을 주어서, 각 트윗에 점수를 부여한다. 각 라벨은 참여 확률(probabilty of engagement) 을 나타내며 이 스코어를 가지고 순위를 매긴다.
Hueristics & Filters
랭킹 단계가 끝난 후, 휴리스틱과 필터링을 적용해서 균형 있고 다양한 피드가 생성될 수 있게 한다.
예를 몇 개 보면 쉽게 이해될 것 같다.
- 차단한 사용자의 트윗은 보지 않게 하는 Visibility 필터링
- 같은 사람이 쓴 연속적인 트윗은 피하도록 하는 Author Diversity 기능
- In-Network 와 Out-Network 트윗들이 균형있게 전달되는 지에 대한 콘텐츠 Balance
Mixing
프로세스의 마지막 단계에서, 시스템은 트윗과 non-트윗(광고, 팔로우 추천 등) 콘텐츠를 함께 섞어서 디바이스에 나타나도록 한다. 이 파이프라인은 하루 약 50억 번 실행되며 평균 1.5초 이하로 완료된다. 단일 파이프라인 실행에는 CPU 시간으로 220 초 정도 걸린다고 한다.
Reference
- https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm
- https://www.digitaltoday.co.kr/news/articleView.html?idxno=473090
- https://github.com/twitter/the-algorithm
댓글남기기